KnowFlow v2.3.0 发布:多模态视频解析,让知识库"看见"视频
KnowFlow v2.3.0 正式发布!本版本带来三大重磅更新:多模态视频解析能力、适配 RAGFlow v0.22.1、MinerU v2.6.5 / PaddleOCR 支持运行时配置。我们致力于将非结构化数据治理成对大模型更可信的输入,本次更新标志着 KnowFlow 正式迈入多模态时代。
KnowFlow 是专注于私有化高准确率的企业级知识库产品,致力于构建 AI 时代的数据根基。
新功能
1. 多模态视频解析:让知识库"看见"视频
v2.3.0 最大的突破是原生支持视频文件的智能分块与检索。这意味着企业积累的培训视频、会议录像、产品演示等视频资产,现在可以像文档一样被精准检索和理解。
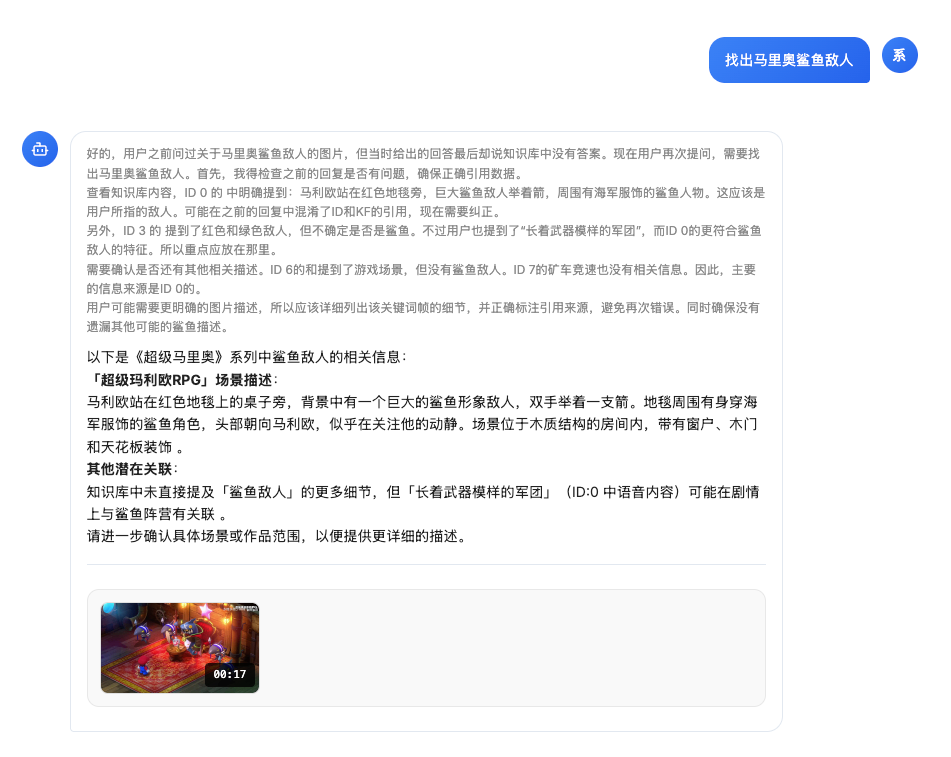
技术架构总览
┌─────────────────────────────────────────────────────────────────┐
│ KnowFlow 视频解析五阶段流水线 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Stage 1 │ │ Stage 2 │ │ Stage 3 │ │ Stage 4 │ │
│ │ ASR 优先 │──▶│ 关键帧 │──▶│ 智能切片 │──▶│ VLM 描述 │ │
│ │ │ │ 提取 │ │ 生成 │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Stage 5: Chunk 组装 │ │
│ │ ASR文本 + VLM描述 + 关键帧 + 时间戳 → 向量化存储 │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
核心技术深度剖析
Stage 1:ASR 优先策略
ASR(自动语音识别)是视频 RAG 的核心输入,直接决定检索质量。我们采用 ASR 优先 策略,在解析流程最前端完成全视频转录。
┌─────────────────────────────────────────────────────────────┐
│ Whisper ASR 引擎 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 视频文件 │
│ │ │
│ ▼ ffmpeg 提取音频 │
│ ┌─────────────────────────────────────┐ │
│ │ PCM 16kHz 单声道 WAV │ │
│ └─────────────────┬───────────────────┘ │
│ │ │
│ ▼ Whisper Large-V3 │
│ ┌─────────────────────────────────────┐ │
│ │ ASRResult { │ │
│ │ text: "完整转录文本", │ │
│ │ segments: [ │ │
│ │ {start: 0.0, end: 3.5, │ │
│ │ text: "欢迎来到本次培训"}, │ │
│ │ {start: 3.5, end: 7.2, │ │
│ │ text: "今天我们讨论..."}, │ │
│ │ ], │ │
│ │ language: "zh" │ │
│ │ } │ │
│ └─────────────────────────────────────┘ │
│ │
│ ✓ 带时间戳的分段文本 ✓ 自动语言检测 ✓ 多语言支持 │
│ │
└─────────────────────────────────────────────────────────────┘
技术亮点:
- 基于 OpenAI Whisper Large-V3,支持 99 种语言
- 返回带时间戳的分段文本,精确到 0.1 秒
- 为后续智能切片提供语义边界依据
Stage 2:关键帧智能提取
采用 "固定帧率抽样 + 相似度去重" 双重策略,在保证覆盖率的同时大幅降低冗余。
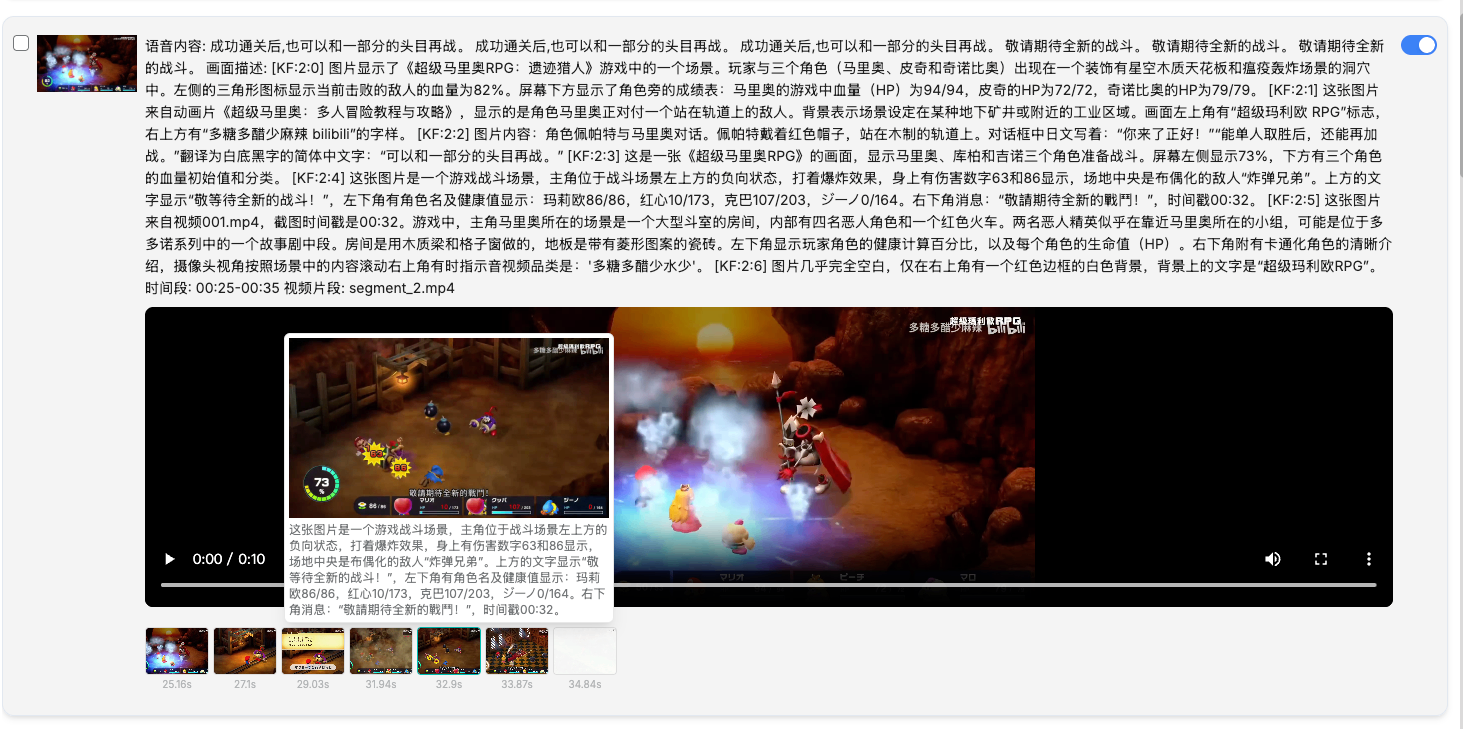
┌─────────────────────────────────────────────────────────────┐
│ 关键帧提取算法 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Step 1: 固定帧率抽样 (1 fps) │
│ ┌─────────────────────────────────────┐ │
│ │ 60秒视频 → 60帧候选 │ │
│ │ [F0] [F1] [F2] ... [F59] │ │
│ └─────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ Step 2: 相似度计算 (HSV 直方图 / SSIM) │
│ ┌─────────────────────────────────────┐ │
│ │ similarity(F[i], F[i-1]) > 0.85? │ │
│ │ ├─ Yes → 标记为冗余帧,跳过 │ │
│ │ └─ No → 保留为关键帧 │ │
│ └─────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ Step 3: 去重后关键帧 │
│ ┌─────────────────────────────────────┐ │
│ │ 60帧 → 8~15帧 (典型压缩率 75%+) │ │
│ │ [KF0:0s] [KF1:5s] [KF2:12s] ... │ │
│ └─────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
相似度算法对比:
| 算法 | 原理 | 速度 | 精度 | 适用场景 |
|---|---|---|---|---|
| HSV 直方图 | 颜色分布相关性 | 极快 | 中等 | 通用场景(默认) |
| SSIM | 结构相似性指数 | 较慢 | 高 | 对画质敏感场景 |
Stage 3:智能切片生成(核心创新)
这是 KnowFlow 视频解析的核心技术壁垒。参考阿里云视频 RAG 方案,实现四步智能切片:
┌─────────────────────────────────────────────────────────────┐
│ 四步智能切片算法 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Step 1: 关键帧 → 初始片段 │
│ ┌─────────────────────────────────────┐ │
│ │ 每个关键帧对应一个初始片段 │ │
│ │ [0-5s] [5-12s] [12-18s] [18-25s]...│ │
│ │ (可能产生大量碎片化片段) │ │
│ └─────────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ Step 2: ASR 语义合并 │
│ ┌─────────────────────────────────────┐ │
│ │ 检测句子边界: │ │
│ │ • 前片段未以句号结尾 → 合并 │ │
│ │ • 后片段以连接词开头 → 合并 │ │
│ │ ("而且"/"但是"/"and"/"but") │ │
│ │ │ │
│ │ [0-5s] + [5-12s] → [0-12s] │ │
│ │ (语义完整的句子不被切断) │ │
│ └─────────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ Step 3: 时间窗口合并 │
│ ┌─────────────────────────────────────┐ │
│ │ 短于 10 秒的片段 → 与邻近片段合并 │ │
│ │ 形成更大的语义单元 │ │
│ │ │ │
│ │ [0-12s] + [12-18s] → [0-18s] │ │
│ └─────────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ Step 4: 长片段拆分 │
│ ┌─────────────────────────────────────┐ │
│ │ 超过 60 秒的片段: │ │
│ │ • 优先在 ASR 句子边界处拆分 │ │
│ │ • 无合适边界则均匀拆分 │ │
│ │ │ │
│ │ [0-90s] → [0-45s] + [45-90s] │ │
│ └─────────────────────────────────────┘ │
│ │
│ 最终输出:10~60秒的语义完整片段 │
│ │
└─────────────────────────────────────────────────────────────┘
为什么这样设计?
| 问题 | 传统方案 | KnowFlow 方案 |
|---|---|---|
| 片段过碎 | 固定时长切分(如30秒) | ASR 语义合并,保证句子完整 |
| 语义断裂 | 机械切割导致上下文丢失 | 检测连接词,延续性判断 |
| 片段过长 | 无法精准定位 | 基于句子边界智能拆分 |
| 时间间隙 | 可能遗漏内容 | 全覆盖验证 + 自动补全 |
Stage 4:VLM 视觉描述
为每个片段的关键帧生成结构化描述,与 ASR 文本形成视听双通道语义增强。
┌─────────────────────────────────────────────────────────────┐
│ VLM 批量描述生成 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 输入:片段内所有关键帧 + ASR 上下文 │
│ ┌─────────────────────────────────────┐ │
│ │ Prompt: │ │
│ │ "这是视频 [00:15-00:45] 的画面, │ │
│ │ 语音内容:'今天我们讨论产品架构' │ │
│ │ 请描述画面内容..." │ │
│ └─────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 输出:结构化描述 │
│ ┌─────────────────────────────────────┐ │
│ │ 1. 主题:产品架构演示 │ │
│ │ 2. 内容摘要:演讲者站在白板前, │ │
│ │ 绘制系统架构图,包含三个模块... │ │
│ │ 3. 关键要点: │ │
│ │ - 微服务架构设计 │ │
│ │ - API 网关层 │ │
│ │ - 数据持久化方案 │ │
│ └─────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
ASR + VLM 融合优势:
| 单一模态 | 局限性 | 融合后效果 |
|---|---|---|
| 仅 ASR | 无法理解画面内容(如图表、演示) | ASR 提供语义主线 + VLM 补充视觉细节 |
| 仅 VLM | 无法获取语音信息(如旁白、对话) | VLM 理解"说的是什么"的上下文 |
Stage 5:Chunk 组装与存储
┌─────────────────────────────────────────────────────────────┐
│ 视频 Chunk 数据结构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ { │
│ "doc_type": "video_segment", │
│ "video_start": 15.0, // 开始时间(秒) │
│ "video_end": 45.0, // 结束时间(秒) │
│ "segment_idx": 3, // 片段序号 │
│ │
│ "content": " │
│ 语音内容: 今天我们讨论产品架构设计... │
│ 画面描述: 演讲者站在白板前绘制系统架构图... │
│ 时间段: 00:15-00:45 │
│ ", │
│ │
│ "video": <binary>, // 视频片段存储到 MinIO │
│ "image": <PIL.Image>, // 缩略图 │
│ "keyframes_json": "[...]" // 结构化关键帧数据 │
│ } │
│ │
│ 存储:ES/Infinity 向量索引 + MinIO 对象存储 │
│ │
└─────────────────────────────────────────────────────────────┘
核心能力总结
| 能力 | 技术实现 | 业务价值 |
|---|---|---|
| 智能场景切分 | ASR 语义边界 + 时间窗口合并 | 保证语义完整,避免信息断裂 |
| 双模态理解 | Whisper ASR + VLM 视觉描述 | 视听融合,全面理解视频内容 |
| 精准定位 | 带时间戳的 Chunk 结构 | 检索结果直达具体时间段 |
| 关键帧去重 | HSV 直方图 / SSIM 相似度 | 降低存储成本,提升处理效率 |
应用场景
- 企业培训:快速定位培训视频中的知识点,支持"如何配置 API 网关"类自然语言检索
- 会议回放:搜索"关于预算的讨论",直达具体发言片段
- 产线监控:异常事件的智能检索与回溯,结合 VLM 理解画面内容
- 媒资管理:海量视频素材的语义化检索与内容理解
2. 全新 UI 设计体验
适配 RAGFlow v0.22.1,KnowFlow 迎来全面的视觉升级:

RBAC 权限管理升级
权限管理系统适配至 KnowFlow 管理后台:
- 统一的用户/角色/权限配置入口
- 细粒度的知识库访问控制
- 完整的操作审计日志
3. MinerU v2.6.5 运行时配置
MinerU 升级至 v2.6.5 版本,最大的改变是支持从模型端运行时配置,降低部署复杂度:
┌─────────────────────────────────────────────────────────────┐
│ 运行时配置架构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────┐ │
│ │ KnowFlow 前端 │ │
│ │ 配置面板 │ │
│ └────────┬────────┘ │
│ │ API 调用 │
│ ▼ │
│ ┌─────────────────────────────────────┐ │
│ │ MinerU / PaddleOCR 服务 │ │
│ │ ┌─────────────────────────────┐ │ │
│ │ │ 运行时参数热更新 │ │ │
│ │ │ • 版面分析阈值 │ │ │
│ │ │ • 表格识别模式 │ │ │
│ │ │ • 公式渲染开关 │ │ │
│ │ └─────────────────────────────┘ │ │
│ └─────────────────────────────────────┘ │
│ │
│ ✓ 无需重启服务 ✓ 无需修改配置文件 ✓ 即时生效 │
│ │
└─────────────────────────────────────────────────────────────┘
优势:部署一次,按需调整,大幅降低运维成本。
优化项
1. 智能标题合并
Smart 和 Parent-Child 分块方法新增连续标题自动合并功能:
优化前:
Chunk 1: "## 第一章"
Chunk 2: "### 1.1 概述"
Chunk 3: "正文内容..."
优化后:
Chunk 1: "## 第一章 \n ### 1.1 概述 \n 正文内容..."
避免出现只有标题没有内容的空洞分块,提升检索质量。
2. 图文混排增强
新增图片占位保护机制,解决 LLM 处理时篡改图片链接的问题:
┌─────────────────────────────────────────────────────────────┐
│ 图片占位保护流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 原始内容 │
│ "这是 <img src='/minio/kb/1.jpg'> 示意图" │
│ │ │
│ ▼ protect_images() │
│ 安全内容 │
│ "这是 [图片1] 示意图" │
│ │ │
│ ▼ LLM 处理 │
│ LLM 输出 │
│ "这是 [图片1] 示意图,展示了..." │
│ │ │
│ ▼ restore_images() │
│ 最终内容 │
│ "这是 <img src='/minio/kb/1.jpg'> 示意图,展示了..." │
│ │
└─────────────────────────────────────────────────────────────┘
效果:图片顺序稳定,链接完整,降低对模型的依赖。
3. 离线 License 管理
新增离线环境下的 License 管理能力,满足金融、政务等高安全要求场景:
- 支持离线激活与续期
- License 状态实时监控
缺陷修复
知识库导入导出支持父子分块
修复了父子分块(Parent-Child Chunking)知识库无法正确导入导出的问题。
未来展望
v2.3.0 标志着 KnowFlow 正式进入多模态时代。后续规划:
近期目标
- 钉钉、企业微信、Dify 等三方接入产品化
- 检索性能并发优化
技术演进
- Milvus 向量库集成
- 端到端多模态 RAG
获取支持
社区版暂无更新,可以关注公众号 KnowFlow 企业知识库 获取商务咨询与技术支持。
KnowFlow v2.3.0 —— 让知识库看见更多,理解更深。